从上一代GPU开始,AMD的顶级产品就采用了与主流产品不同的架构,以采用更多的流水线,即所谓的“大核心”设计,同时搭配超高带宽的HBM(High Bandwidth Memory,高带宽内存)显存。在这一代GPU产品线上,AMD仍然采用了这一模式,即在低端到主流市场使用Polaris核心,而高端和旗舰级则使用刚刚推出的VEGA架构。
VEGA架构中的的基础单元为NCU(Next-Generation Computer Unit,下一代计算单元),它仍然是基于GCN的改进,改进重点当然仍是提高效率。在NCU单元中加入了快速堆叠运算(RPM,Rapid Packed Math),可以将不同带宽的兼容指令进行打包处理,因此每一个NCU中的64个32位处理单元每个时钟周期最多可以同时处理512个8位、256个16位或者128个32位操作,提高了计算单元的利用率和总体性能。
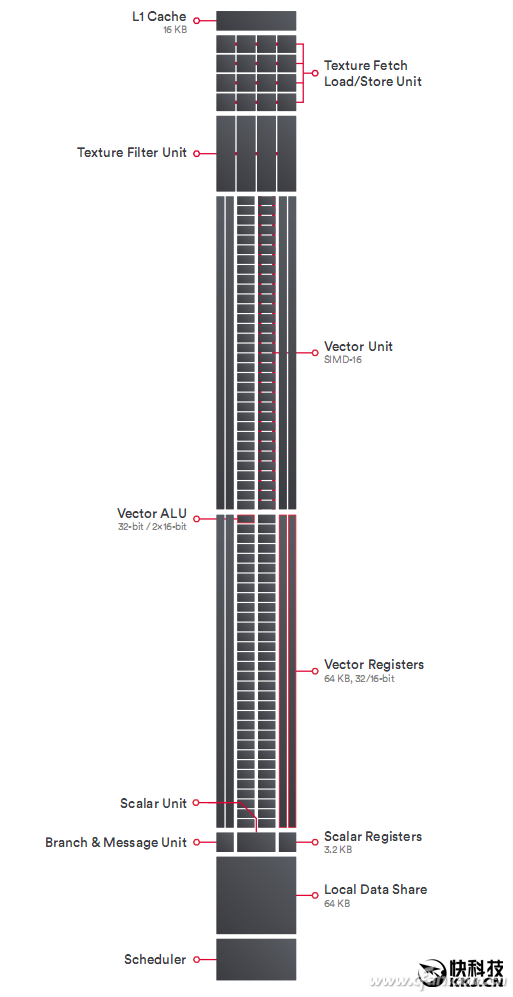
NCU单元架构
VEGA的几何引擎可以更高效地抛弃不可见的、没必要处理的元素,新的智能负载分配器则会根据实际情况持续调整流水线设定,更好地平衡各个几何引擎之间的负载,提高利用率。它配有流式传输光栅器(DSBR,Draw Stream Binning Rasterizer),可以通过消除非必要的数据和处理来提升处理效率,降低功耗。VEGA核心将纹理和像素的存取统一,也提升了缓存的效率及使用率,可以更好地满足目前超高分辨率和刷新率以及VR显示的需求。
VEGA核心内置4MB二级缓存,配有更高频率和容量的HBM2显存,不过目前的版本考虑到成本问题,采用两颗显存的堆叠方式,显存位宽相对于4显存显存的Fiji反而更低一些。它还带有高带宽缓存控制器(HBCC),可将系统内存作为显示缓存使用,并且会优化这部分内存的管理机制,使其更适合作为显示缓存,这在一定程度上解决了HBM成本较高,VEGA显卡自带显存容量较少的问题。
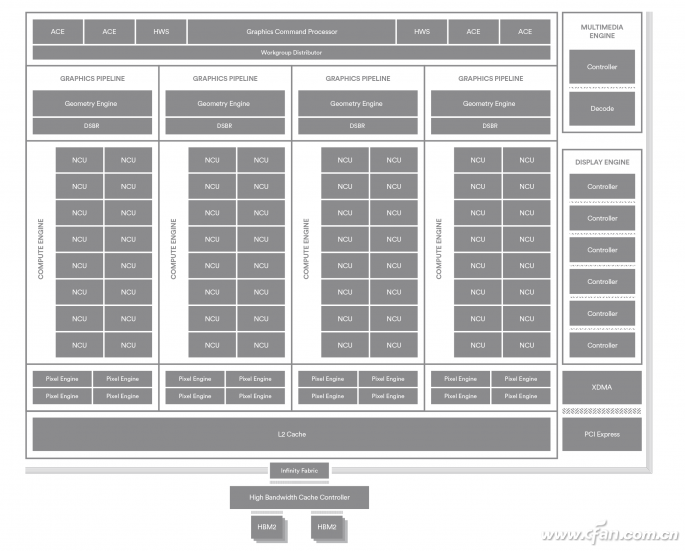
VEGA核心架构示意图
VEGA 10也是AMD第一款采用“Infinity Fabric”技术的GPU,该技术将GPU内部的显存控制器、PCI-E控制器、显示引擎和视频加速模块等主要逻辑模块连接起来。这种模块化的设计让GPU可以根据客户的不同需求进行变换,并且也加强了PCI-E控制器等模块的性能,让HBCC可以更高效地使用系统内存。另外VEGA也会完全支持最新的DirecX 12.1,在可选技术的支持方面还高于Pascal。